
Veröffentlicht am10 Aug 2020
min lesen
Ansichten

Ich bin sicher, dass die meisten von uns auf die eine oder andere Weise schon einmal Probleme mit der Dateninkonsistenz in einem Softwaresystem hatten. Wenn man zum Beispiel einen Geldautomaten bedient, um Geld abzuheben, kommt es häufig vor, dass Transaktionen aus verschiedenen Gründen fehlschlagen. Es kann sein, dass der Geldautomat das Geld nicht ausgibt, obwohl der Saldo auf den Konten abgezogen wird. Wenn Kunden den Fehler im System melden, antwortet die Bank in der Regel, dass es 60 Minuten bis 24 Stunden dauern wird, bis der fehlerhafte Transaktionsdatensatz behoben ist. Dies ist ein typischer Fall von Dateninkonsistenz, bei dem der Geldautomat und der Bankserver für einen kurzen Zeitraum nicht synchronisiert sind.
Nehmen wir einen anderen Fall einer Rechnungszahlung über eine Handy-App. Der Nutzer veranlasst die Zahlung, die App stellt eine sichere Verbindung zur Bankschnittstelle her, die Zahlung wird verarbeitet und an die Schnittstelle des Händlers weitergeleitet, um die Zahlung zu bestätigen. Angenommen, die Website des Händlers ist in diesem Moment nicht verfügbar. Nun bleibt die Transaktion für einen kurzen Zeitraum unvollständig, bis sich die App-Server mit der Schnittstelle des Händlers synchronisiert haben.
In beiden Fällen sind die Dateninkonsistenzen darauf zurückzuführen, dass bestimmte Teile des Systems nicht verfügbar sind, Dienste nicht reagieren, netzwerkbedingte Fehler auftreten usw. Diese Faktoren sind in großen verteilten Softwaresystemen sehr häufig. Auch wenn das System im Laufe der Zeit Konsistenz herstellt, ist ein nahtloser und reibungsloser Ablauf für den Endbenutzer nicht sicher.
Die Microservices-Architektur verfolgt einen verteilten Ansatz, bei dem jeder Dienst bzw. jede Funktion einer Software in hohem Maße unabhängig ist, eine bestimmte Geschäftsgrenze oder einen definierten Kontext hat, von der Existenz anderer Dienste wissen kann oder nicht, seine eigenen Daten verwalten kann, verschiedene Speichermechanismen verwenden kann und möglicherweise in verschiedenen Programmiersprachen verfasst und von separaten Teams gepflegt wird.
Die Microservices-Architektur verwendet einen dezentralen Ansatz und ist stark von der Natur inspiriert. Microservices sind eine beliebte Wahl für den Aufbau großer Unternehmenssysteme geworden. Mit dem Aufkommen der Cloud, der elastischen Datenverarbeitung und -speicherung sowie der Containertechnologie und der Orchestrierungsmechanismen gibt es einen enormen Anstieg bei der Erstellung von Anwendungen im Stil der Microservices-Architektur.
Inzwischen haben Sie vielleicht schon herausgefunden, dass die Microservices-Architektur aufgrund ihrer starken Befürwortung eines dezentralen Datenansatzes die Datenkonsistenz in den Systemen fördert. Es wäre jedoch unklug zu glauben, dass die monolithische Softwarearchitektur diese Probleme nahtlos löst. Sie haben ihre eigenen Gefahren.
Es ist daher unerlässlich, dass die Entwickler von Microservices diese Probleme berücksichtigen und sich der Herausforderungen bewusst sind, die sich bei der Datenkonsistenz einschleichen können. Die unten aufgeführten Techniken helfen bei der Verwaltung der eventuellen Konsistenz in Microservices.
Saga-Muster
Transaktionen, die sich über mehrere Dienste erstrecken, werden als eine Saga/Kette einfacher lokaler atomarer Transaktionen auf jeder Dienstebene betrachtet. So schließt ein Dienst seine Transaktion ab und setzt sie fest, benachrichtigt den nächsten Dienst in der Kette mit einem Ereignis/einer Nachricht, um die nächste lokale Transaktion auszulösen, und so weiter und so fort. Wenn eine Transaktion in dieser Kette aus irgendeinem Grund fehlschlägt, löst sie im Grunde eine Rückgängigmachung aus, die in der Kette nach hinten führt. Es ist daher zwingend erforderlich, bei der Entwicklung der Architektur Musterfehler zu berücksichtigen.
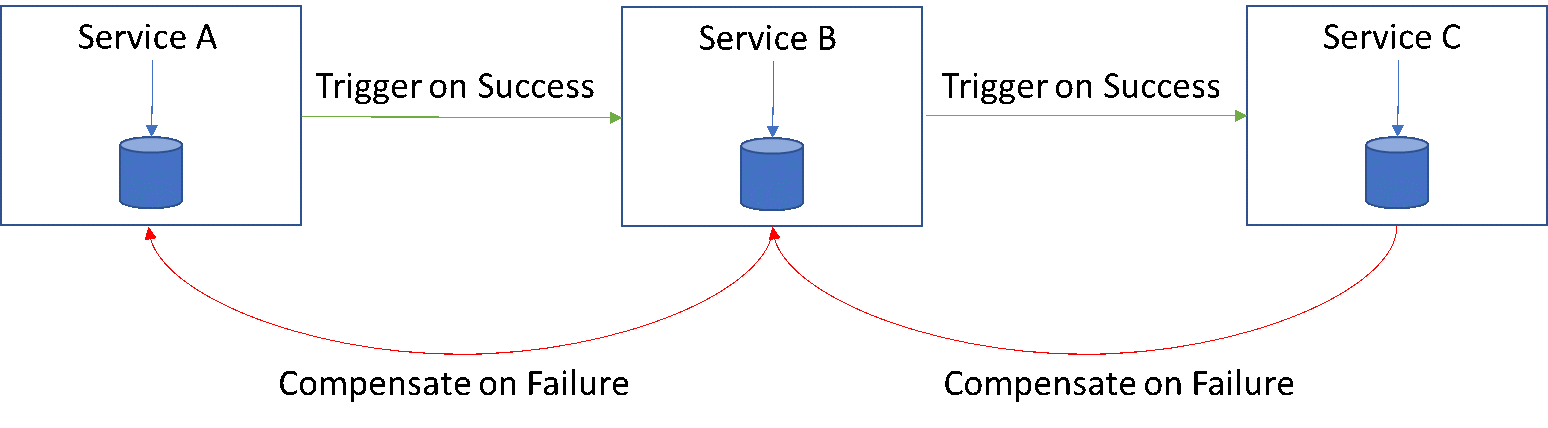
Das Saga-Muster geht zwar auf eventuelle Konsistenzprobleme ein, ist aber eher für kleinere verteilte Architekturen als für große geeignet. Die Entwickler müssen auch berücksichtigen, dass Kompensationsaufrufe/Transaktionen auch fehlschlagen können. Daher ist es für einfachere und kleine verteilte Architekturen geeignet.
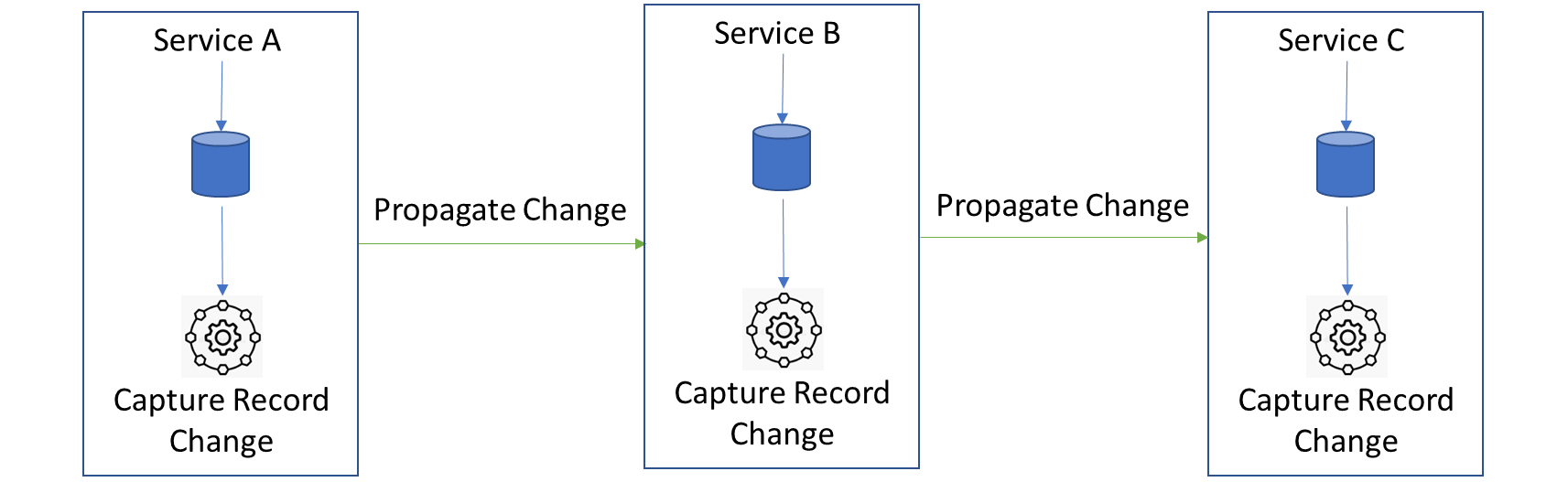
Änderungsdatenerfassung (CDC)
CDC ist zwar im Data Warehousing fest verwurzelt und wird dort ausgiebig praktiziert, kann aber auch für das Design von Microservices übernommen werden, um sicherzustellen, dass die Transaktionen die Services konsistent überspannen.
Das Grundprinzip bleibt im Kern gleich. Ein Dienst löst, nachdem seine lokale Transaktion in die lokale DB übertragen wurde, einen separaten Prozess aus, der einen Change Capture Record erstellt und den Change Capture Record an den nächsten Dienst weitergibt. Dieser Dienst nimmt den Change-Capture-Datensatz des vorherigen Dienstes auf, verarbeitet ihn, überträgt ihn in seine lokale DB und erstellt in einem separaten Prozess seinen eigenen neuen Change-Capture-Datensatz, den er an die nächste Gruppe von Diensten weitergibt.
Auf diese Weise kann dieser Change-Capture-Datensatz durch die verteilten Dienste propagiert werden, bis alle Dienste synchronisiert sind, ohne dass die Orchestrierung übermäßig belastet wird.
Möglichkeiten zur Implementierung von CDC in Microservices:
Verwendung von Datenbank-Transaktionsprotokollen: Viele Datenbanken bieten Betriebsprotokolle und Transaktionsprotokolle. Durch Scannen des Inhalts dieser Protokolle und Interpretation der Änderungen kann man die an der Datenbank vorgenommenen Änderungen identifizieren. Dies kann der Änderungserfassungssatz sein, der an den nächsten Dienst weitergegeben wird.
Verwendung von Kafka Connect und Apache Kafka: Die in einem Dienst erfassten DB-Änderungen können mit einem Kafka-Connecter verbunden werden, der die Änderungen an die verschiedenen Kafka-Themen weiterleitet, damit die Abonnenten sie konsumieren und umsetzen können.
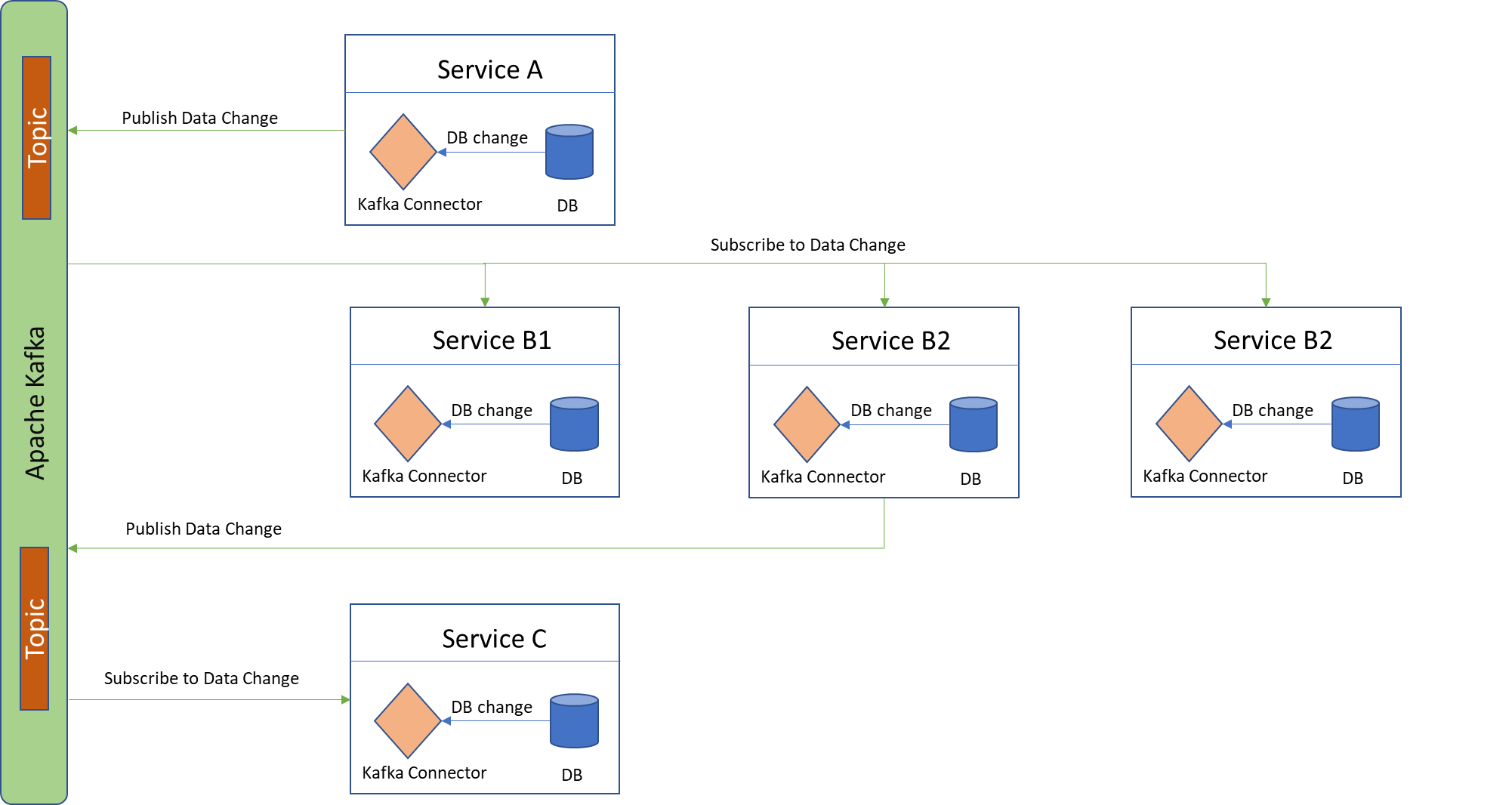
CDC eignet sich im Allgemeinen für große verteilte Architekturen, da es nicht leistungsintensiv ist und leicht aktiviert werden kann, ohne dass zusätzliche Änderungen am Schema vorgenommen werden müssen. CDC hat von Natur aus eine geringere Latenzzeit und ermöglicht es nachgelagerten Datenbanken, die Änderungen schnell zu verfolgen. Es besteht auch die Möglichkeit, den von den Diensten empfangenen Änderungsfeed als Stream zu verarbeiten.
Der größte Nachteil, den die Entwickler bei CDC sehen, ist jedoch die Unflexibilität bei der Änderung des Schemas der Dienste. Dadurch wird die Entwicklung des DB-Schemas der Dienste in gewissem Maße blockiert. Die Änderung des Schemas in einem Dienst löst Änderungen in allen nachgelagerten Diensten aus.
Neben diesen beiden Möglichkeiten gibt es noch mehrere andere Wege, um eine Datensynchronisation durch CDC zu erreichen, die von Cloud-Infrastrukturanbietern implementiert wurden.
Einschlägige Blogs

Mehr als Effizienz: Intelligente Fabriken als nächster Wettbewerbsvorteil für die Luft- und Raumfahrt
Mehr als Effizienz: Intelligente Fabriken als nächster Wettbewerbsvorteil für die Luft- und Raumfahrt