
公開日10 Aug 2020
最小読み取り時間
ビュー

私たちの多くは、何らかの形で、ソフトウェア・システムにおけるデータの不整合問題を経験したことがあると思う。例えば、お金を引き出すためにATM機を操作していると、様々な理由で取引に失敗することがよくある。ATMマシンは通貨を払い出さないかもしれないが、口座の残高引き落としが表示されるかもしれない。顧客がシステムに障害を報告すると、銀行は通常、誤った取引記録を解決するのに60分から24時間かかると回答する。これは、ATMと銀行のサーバーが短時間同期していない典型的なデータ不整合のケースである。
携帯電話アプリを使った請求書支払いのケースを見てみよう。ユーザーが支払いを開始すると、アプリは銀行のインターフェースに安全に接続し、支払いが処理され、支払いを確認するために加盟店のインターフェースに引き渡される。この時、加盟店のウェブサイトが利用できないとしよう。この場合、アプリのサーバーが加盟店のインターフェイスと同期するまでのしばらくの間、取引は未完了のままとなる。
上記のどちらのケースでも、データの不整合はシステムの特定の部分が利用できない、サービスが応答しない、ネットワークに起因するエラーなどによるものであり、これらの要因は大規模な分散ソフトウェアシステムでは非常に一般的であることに注意してください。このような要因は、大規模な分散型ソフトウェア・システムにはよくあることです。システムは最終的には一定期間をかけて一貫性を確立しますが、シームレスで手間のかからないエンドユーザー体験は確実ではありません。
ソフトウェア・アーキテクチャを構築するマイクロサービス・スタイルは、ソフトウェアの各サービス/機能が高度に独立し、特定のビジネス境界または定義されたコンテキストを持ち、他のサービスの存在を知っていても知らなくてもよく、独自のデータを管理することができ、異なる保存メカニズムを使用することができ、異なるプログラミング言語で作成される可能性があり、別々のチームによって保守される分散型アプローチを採用している。
マイクロサービス・アーキテクチャは分散型アプローチを採用しており、自然界から多くのインスピレーションを得ている。マイクロサービスは、巨大な企業システムを構築するための一般的な選択肢となっている。クラウド、エラスティックなコンピューティングとストレージ、コンテナ技術とオーケストレーション・メカニズムの出現により、マイクロサービス・アーキテクチャ・スタイルを使ったアプリケーションの構築が急増している。
マイクロサービス・アーキテクチャが分散型データ・アプローチを強く提唱しているおかげで、システムに最終的なデータの一貫性がもたらされることは、もうお分かりかもしれない。しかし、モノリシックなソフトウェア・アーキテクチャがこれらの問題にシームレスに対処していると考えるのは賢明ではない。モノリシック・ソフトウェア・アーキテクチャにはそれなりの危険性があるのだ。
したがって、マイクロサービス開発者はこれらの問題を考慮し、最終的なデータの一貫性に忍び寄る可能性のある課題を認識しておくことが不可欠です。以下に挙げるテクニックは、マイクロサービスにおける最終的な一貫性の管理に役立ちます。
Sagaパターン
複数のサービスにまたがるトランザクションは、各サービスレベルで単純なアトミックローカルトランザクションのサガ/チェーンとして捉えられる。従って、あるサービスがそのトランザクションを完了しコミットすると、次のローカルトランザクションをトリガーするイベント/メッセージをチェーン内の次のサービスに通知する、といった具合である。このチェーン内の1つのトランザクションが何らかの理由で失敗した場合、基本的にはチェーン内で後方に来る取り消し操作がトリガーされる。そのため、アーキテクチャを設計する際には、パターンの失敗に対処することが不可欠である。
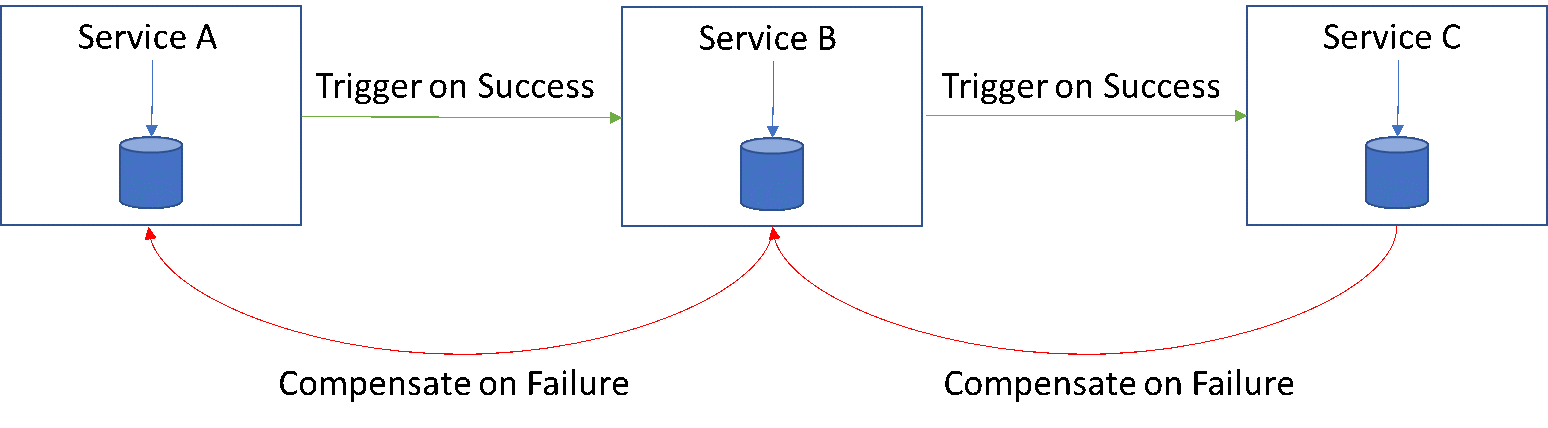
Sagaパターンは、最終的な一貫性の問題には対処しているが、大規模な分散アーキテクチャよりも小規模な分散アーキテクチャに適している。設計者は、補償コールやトランザクションが失敗する可能性も考慮する必要がある。したがって、よりシンプルで小規模な分散アーキテクチャに適している。
変更データ・キャプチャー(CDC)
CDCはデータ・ウェアハウスで広く実践され、根付いているが、トランザクションが一貫性を持ってサービスにまたがることを保証するために、マイクロサービス設計に効果的に採用することができる。
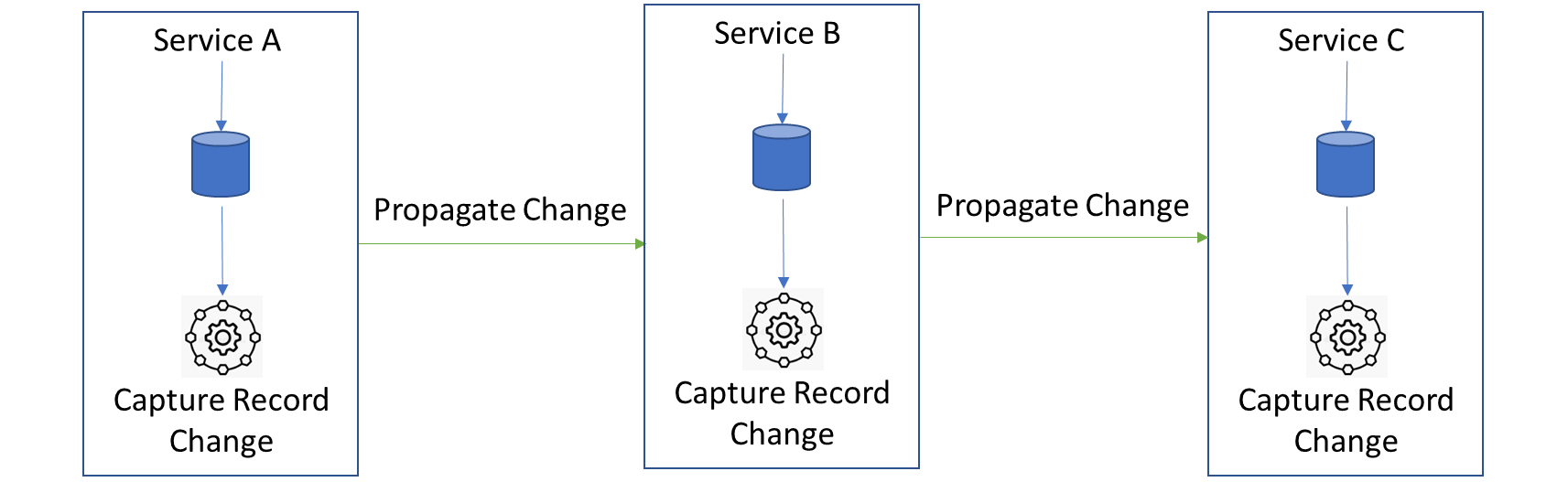
基本原則は変わらない。ローカルトランザクションがローカルDBにコミットした後、サービスは変更キャプチャレコードを作成する別プロセスをトリガーし、変更キャプチャレコードを次のサービスに伝搬する。このサービスは、前のサービスから変更キャプチャレコードを受け取り、それを処理し、ローカルDBにコミットし、その中の別のプロセスで、独自の新しい変更キャプチャレコードを作成し、次のサービスのセットに伝播します。
このように、オーケストレーションに大きな負担をかけることなく、すべてのサービスが同期するまで、この変更キャプチャレコードを分散サービスを通じて伝播することができる。
マイクロサービスでCDCを実装する方法:
データベースのトランザクションログを使う: 多くのデータベースは操作ログとトランザクションログを提供している。これらのログの内容をスキャンし、変更を解釈することで、データベースに加えられた変更を特定することができる。これは次のサービスに伝搬される変更キャプチャ記録となる。
Kafka ConnectとApache Kafkaを使う:サービス内で行われたDBの変更は、Kafkaコネクターにフックすることができる。
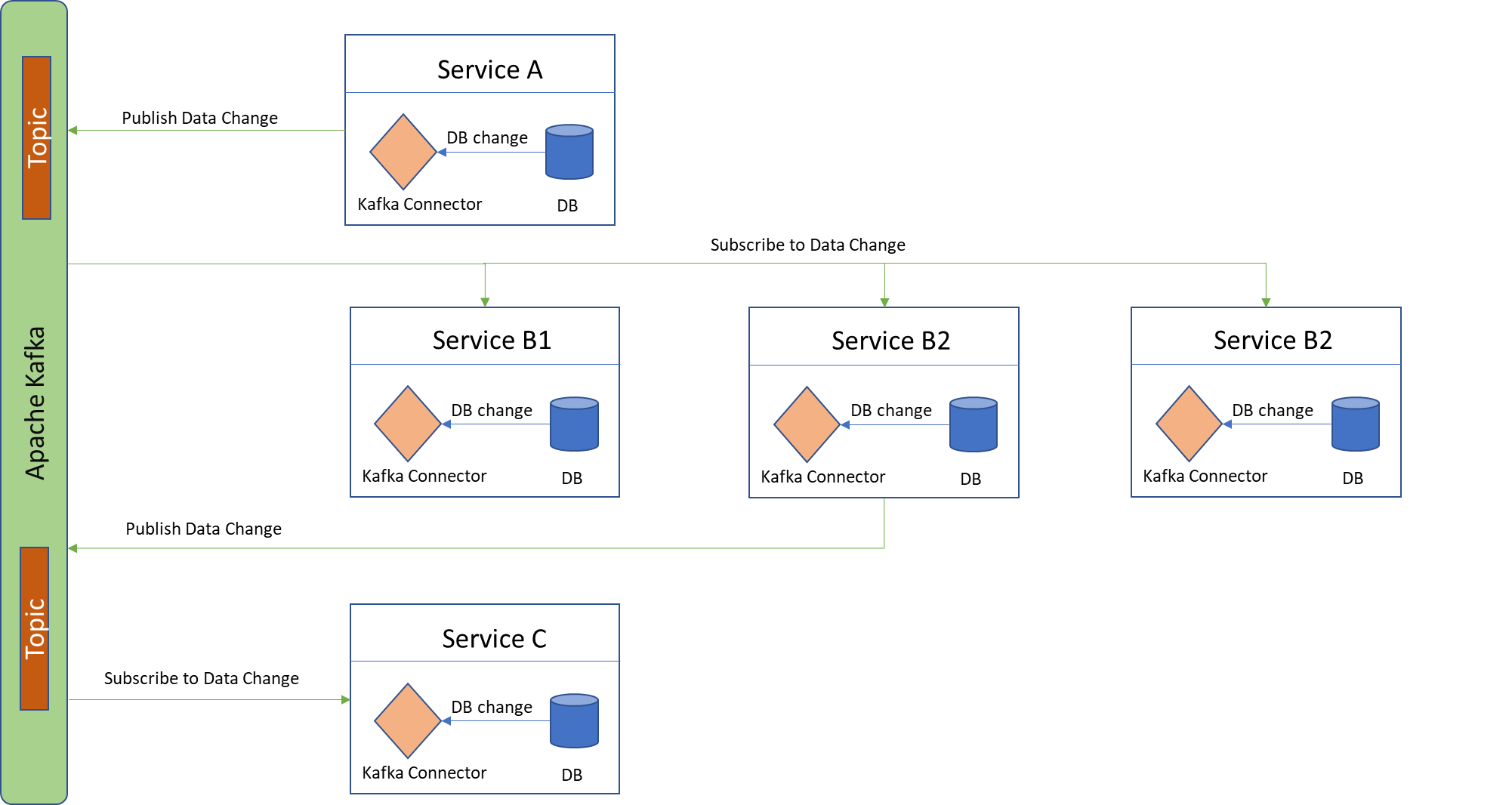
CDCは一般的に、大規模な分散アーキテクチャスタイルに適している。パフォーマンスが重くなく、スキーマに余分な変更を加えることなく簡単に有効にできるからだ。CDCは本質的にレイテンシーが低く、ダウンストリームデータベースが変更を素早く追跡できる。サービスによって受信された変更フィードに対してストリーム処理を実行する可能性もある。
しかし、設計者がCDCに感じている最も重要な欠点は、サービスのスキーマを柔軟に変更できないことである。これはサービスDBのスキーマの進化をある程度阻害する。あるサービスでスキーマを変更すると、下流のすべてのサービスで変更が引き起こされる。
この2つの方法以外にも、クラウド・インフラ・プロバイダーが実装しているCDCによってデータ同期を実現する方法がいくつかある。
データの一貫性と統合を達成するための2つの一般的なアプローチとその欠点を見てきましたが、次にデータの一貫性の問題を見るための全く新しい視点とパラダイムについて考えてみましょう... 「矛盾を受け入れる」 - すべてのソフトウェア・システム/システムの一部が、常にデータを同期させ、一貫性を保つ必要があるわけではありません。ATMでお金を引き出す例に戻ってみよう。私たちは皆、ここでデータの不一致を受け入れ、システムが一定期間一貫性を持つようになるのを待っている。
多くのビジネス・システムは、通常考えられているよりもデータの不整合に寛容である。というのも、企業はサービスの可用性を 重視し、収益を上げているため、 多くのエンタープライズ規模のシステムで ACIDよりも BASEを優先させるという議論が長く続いている。
BASE とは、Basically Available (基本的に 利用可能)、Softstate(ソフトな状態)、EventualConsistency(最終的な一貫性)の頭文字をとったものである。
ACIDとは、Atomicity(原子性)、Consistent(一貫性)、Isolated(分離)、Durable(耐久性)の頭文字をとったもの。
これは、分散データストアが次の3つの保証のうち2つ以上を同時に提供することは不可能であるという、よく知られたCAP定理と一致している。Consistency(一貫性)、Availability(可用性)、Partitiontolerance(分割耐性)。
従って、ソフトウェアシステムは常にACIDよりもBASEを、あるいはその逆を必要に応じて選択し、システムの一部の一貫性を保つ。
この記事に関するコメント、フィードバック、質問など、お気軽にお寄せください。
