Veröffentlicht am12 May 2023
min lesen
Ansichten

Seit 2020 ist die Nachfrage nach virtueller Gesundheitsversorgung um das 38-fache gestiegen. Diese beispiellose Expansion bietet wiederum sowohl erhebliche Chancen als auch Herausforderungen für die großen Gesundheitsunternehmen weltweit.
Das rasante Wachstum hat nicht nur den Multikanal-Zugang zu einem größeren Patientenstamm ermöglicht, sondern auch die Erzeugung riesiger Mengen sensibler gesundheitsbezogener Daten ausgelöst - ein ergiebiges Jagdrevier für Cyber-Bedrohungsakteure. Gleichzeitig stellt die Abhängigkeit von alten, uneinheitlichen Systemen eine Herausforderung für die Integrierbarkeit dar, insbesondere mit dem Aufkommen von telemedizinischen Anwendungen und dem Internet der medizinischen Dinge (Internet of Medical Things, IoMT), die zur Datenvermehrung beitragen.
Die Centers for Medicare & Medicaid Services (CMS) und das Office of the National Coordinator for Health IT (ONC) haben als Reaktion auf das sich entwickelnde Szenario Richtlinien eingeführt, die die Abschaffung der derzeitigen siloartigen Datensysteme vorschreiben. Diese Richtlinien stellen einen Versuch dar, eine nahtlose datengestützte Kommunikation zwischen Krankenhäusern, Ärzten, Kostenträgern, pharmazeutischen Unternehmen und Herstellern von medizinischen Geräten und Ausrüstungenzu ermöglichen - und damit bessere Gesundheitsergebnisse auf breiter Front zu erzielen.
Aus betrieblicher Sicht zwingen die neuen Vorschriften die IT-Teams in Gesundheitseinrichtungen dazu, Interoperabilität als funktionale Softwareanforderung zu etablieren. Der Schwerpunkt liegt dabei auf der nahtlosen und vollständigen bidirektionalen Übertragung von Gesundheitsinformationen, einschließlich Patientendaten, zwischen relevanten und zugelassenen Beteiligten.
Um eine solche Interoperabilität zu erreichen, müssen die heutigen Gesundheitssysteme über eine gemeinsame Schnittstelle kommunizieren können. Angesichts von über 40 Standardentwicklungsorganisationen (SDOs) im IT-Bereich des Gesundheitswesens ist die Wahl des richtigen standardisierten Formats für die Dateninteroperabilität und -speicherung jedoch ein dringendes Problem für Gesundheitsdienstleister. Die rasche Zunahme des Datenvolumens führt daher zu zunehmenden Befürchtungen in der gesamten Branche und veranlasst zu einer verstärkten Nutzung der Cloud - ein Übergang, der die kritische Notwendigkeit eines rationalisierten Datenaustauschs gemäß den standardisierten Interoperabilitätsrichtlinien weiter unterstreicht.
In einer im April 2021 veröffentlichten Umfrage wurde untersucht, wie HCOs ihre Patientendaten speichern. Die Zahlen zeigten, dass die meisten HCOs ihre Daten zwar zentralisieren, aber nur etwa 24 Prozent von ihnen eine zukunftssichere hybride Cloud-Infrastruktur einrichten wollen.

Abbildung 1: Prozentsatz der HCOs, die jede Speicherlösung nutzen
Laut Gartner entwickelt sich die Cloud-basierte Datenspeicherung im Gesundheitswesen selbst in diesem Anfangsstadium zu einem Marktstörer. Es gibt jedoch auch eine gute Nachricht. Unternehmen erkennen zunehmend die Vorteile eines hybriden oder Multi-Cloud-Ansatzes, um potenzielle Cybersicherheitsprobleme zu lösen. Im Jahr 2022 nutzten nur etwa drei Prozent der Unternehmen eine einzige private oder öffentliche Cloud, was im Vergleich zum Höchststand von 29 % im Jahr 2019 deutlich niedriger ist.
Und auch HCOs, die von der traditionellen monolithischen Architektur abrücken und eine dezentralisierte, gemeinsam nutzbare und skalierbare Cloud-Architektur einführen, profitieren von den Vorteilen. Ein wesentlicher Vorteil ist die Unabhängigkeit von starren IT-Infrastrukturen, die die Interoperabilität zwischen Servern einschränken. Ein zweiter Vorteil ist die Flexibilität: die Freiheit, eine hybride/Multi-Cloud-Architektur nach Bedarf zu nutzen, um Gesundheitssysteme zu skalieren und eine beliebige Anzahl von Cloud-Lösungen nach Bedarf einzusetzen.
In Zukunft werden die Fortschritte bei den Cloud-Innovationen, einschließlich der intelligenten Cloud-Integration, der Cloud-fähigen Heimautomatisierung und der autonomen Multi-Cloud-Container-Plattformen, den HCOs das Versprechen einer höheren Wertschöpfung, Sicherheit und Konnektivität geben.
Dieses Szenario ist jedoch nur möglich, wenn alle Funktionen Zugriff auf Erkenntnisse aus einheitlich kategorisierten Daten haben.
IEEE definiert Interoperabilität formell als "die Fähigkeit von zwei oder mehr Systemen oder Komponenten, Informationen auszutauschen und die ausgetauschten Informationen zu nutzen" Diese Definition eröffnet zwei konzeptionelle Ebenen,
- Syntaktische
- Semantische
Syntaktische Interoperabilität ist die Standardisierung der Datenformate und der Kommunikation, die die grundlegende Verknüpfung und Integration zwischen Systemen oder ihren Komponenten ermöglicht. Hier werden die Informationsmodelle für die Verbindung heterogener Datenquellen genutzt, indem gemeinsame Formulare/Standards für das Cross-Mapping verwendet werden.
Die semantische Interoperabilität befasst sich mit den Herausforderungen der genauen Interpretation und Nutzung der durch die syntaktische Interoperabilität ausgetauschten Informationen. Hier liegt der Schwerpunkt auf der Bewältigung der Herausforderungen im Zusammenhang mit benutzerverständlichen, berechenbaren und erweiterbaren Wissensrepräsentationsschemata.
Die Abbildung der digitalen Architektur erfordert einen Interoperabilitätsstandard mit einem einheitlichen Speicher- und Zugriffsformat. HCOs verlassen sich überwiegend auf den Standard Fast Healthcare Interoperability Resources (FHIR) von Health Level 7 (HL7), der den bidirektionalen Datenaustausch sowohl beim Lesen als auch bei der Eingabe von Daten unterstützt. FHIR ermöglicht auch granularere Datentypen und Dokumente und kann für Plug-and-Play-Anwendungen verwendet werden.
APIs für das Gesundheitswesen, wie z. B. Google Healthcare API , nutzen FHIR für die Abbildung und Übertragung von Daten. In einem Beispiel ermöglichte die API einer großen Apotheke eine intensivere Einbeziehung der Patienten bei gleichzeitiger Senkung der Betriebskosten.
FHIR ist seit einiger Zeit der Standard für semantische Interoperabilität, bei dem das System eine gemeinsame Transportmethode für die Datenübertragung verwendet. Echte" Dateninteroperabilität erfordert jedoch auch semantische Interoperabilität, die dem System hilft, elektronische Gesundheitsakten (EHR) zu nutzen, um die genaue Bedeutung und den Kontext der Daten zu verstehen.
Im Laufe der Jahre und mit mehreren Versionen von HL7 ist es FHIR jedoch nicht gelungen, die semantische Interoperabilität zwischen den Versionen aufrechtzuerhalten.
Um den Verlust von Daten bei der Übersetzung zu verhindern, führte ein Konsortium von Gesundheitsdienstleistern eine neue Technologie ein, die auf einer bereichsbezogenen Plattform für Informationssysteme mit klinischen Modellen und Spezifikationen basiert. openEHR half dabei, eine Brücke zwischen Fachleuten und IT-Entwicklern zu schlagen und eine feste Bedeutung für jeden Datentyp festzulegen. Die E-Health-Technologie ermöglichte eine schnelle Anwendungsentwicklung durch Low-Code-Tools, und gleichzeitig trugen die vorkonfigurierten komponentenorientierten Schnittstellen zur kosteneffizienten Interoperabilität bei.
Um dies besser zu verstehen, konzentriert sich das Hauptziel von FHIR auf die Schaffung eines System-zu-System (B2B) und eines System-zu-Anwendung (B2C) Nexus. Der B2B-Teil ist im Wesentlichen ein informationsbasierter Ansatz, während der B2C-Teil die grundlegenden Anforderungen zur Erleichterung moderner Anwendungen im Gesundheitswesen erfüllt.
FHIR hat eine größere API-Abdeckung und ist ein innovatives Projekt, das hervorragende Arbeit bei der Schaffung von APIs für komplexe Aufgaben geleistet hat.
Andererseits bietet openEHR eine umfassende Abdeckung von Patienteninformationen und eine erhebliche Abdeckung des Bereichs der klinischen Modelle. Allerdings ist die API-Kompatibilität begrenzt.
Das Hauptziel von openEHR ist es, die Herausforderungen im Zusammenhang mit dauerhaften und berechenbaren Aufzeichnungen innerhalb eines Open-Source-Patientenverwaltungssystems zu bewältigen. Dies stellt eine langfristige und zukunftsorientierte Herausforderung dar, die wiederum durch die Nutzung der Prinzipien der Plattformarchitektur angegangen wird. Dabei ist zu bedenken, dass openEHR selbst nur einige Elemente dieser Plattform bietet, die ihrerseits Zugang zu geeigneter Terminologie, Arzneimitteldatenbanken und relevanten Service-Schnittstellen haben muss.
Während die meisten HCOs FHIR kennen und nutzen, gewinnt openEHR aufgrund seiner Robustheit und Anpassungsfähigkeit an Aufmerksamkeit. Bei meinen Gesprächen mit Fachleuten aus der Branche haben wir festgestellt, dass die Verwendung von FHIR und EHR im Allgemeinen verwirrend ist. Und um ihre Verwendung zu erklären, ist es am besten, sie in die Perspektive der Cloud-Adoption zu stellen. Nachfolgend sind einige FHIR-Herausforderungen aufgeführt, die openEHR für HCOs lösen kann, die eine Skalierung oder Migration zu Cloud-Umgebungen anstreben.
Die erste Herausforderung ist die Robustheit des Datenmodells. FHIR kann Daten für bestimmte Anwendungsfälle modellieren und speichern. Wenn es sich bei den Datenmengen jedoch um breite und komplexe Kategorien handelt, ist openEHR ein besserer Standard. Wenn es beispielsweise um die Speicherung von Beobachtungsdaten für Patienten geht, kann FHIR ein paar generische Ressourcen bereitstellen. openEHR hingegen verfügt über eine vorgefertigte Vorlage zur Beobachtung eines bestimmten Zustands auf der Grundlage mehrerer Parameter, einschließlich Körpertemperatur, Blutdruck und Herzfrequenz.
Die zweite Herausforderung sind Business Intelligence und Analytik. FHIR verfügt über einen Standardsatz von REST-APIs, die IT-Entwickler zur Untersuchung von Datensätzen verwenden. Dieser Ansatz zur Abfrage von Daten erfordert eine direkte Kommunikation mit der API, die ein Verständnis der komplexen SQL-Dialekte voraussetzt. openEHRs AQL, die native Abfragesprache, bietet stattdessen eine Schnittstelle zur Erkundung von Daten. Dies eignet sich jedoch nicht für alle analytischen Anwendungsfälle, bei denen die Daten auf unterschiedliche Weise bearbeitet werden müssen.
Die dritte Herausforderung ist, wie bereits kurz erwähnt, die Versionierung. Neue Versionen der HL7-Standards haben die Semantik der modellierten Daten verändert. Bei der Ressource AllergyIntolerance wurde beispielsweise "assertedData" in "recordedDate" geändert, was sich semantisch vom früheren Modell unterscheidet. Dies stellt ein großes Problem dar, wenn es um die Modellierung von Daten im FHIR-Format geht. Um dieses Problem zu lösen, müssen die Entwickler entweder eine Übersetzungsschicht einführen oder die gesamten Daten auf die neue Version migrieren. In openEHR ist das Datenmodell durch ein Basisreferenzmodell auf Veränderungen vorbereitet. Es besteht aus einer Reihe von generischen Basisklassen und -typen. Dies ermöglicht der Plattform die Modellierung von klinischen Archetypen und Vorlagen für verschiedene Anwendungsfälle. Die Entwickler von IT-Systemen für das Gesundheitswesen können ihre benötigten Parameter aus den Archetypen und Vorlagen auswählen, um ihr Referenzmodell zu erstellen und so die Modellierungsumgebung innerhalb der Software zu schaffen.
Die obige Diskussion führt uns zu der wichtigen Erkenntnis, dass sowohl FHIR als auch openEHR eine entscheidende Rolle bei der Gewährleistung einer effektiven Interoperabilität in Cloud-Umgebungen spielen. Eine zukunftsorientierte digitale Architektur in der Cloud muss mit FHIR und openEHR abgebildet werden (Abbildung 2), um die Produktivität, Benutzerfreundlichkeit und Flexibilität deutlich zu verbessern. FHIR und openEHR können entsprechend den spezifischen Anwendungsfällen und Anforderungen abgebildet werden.
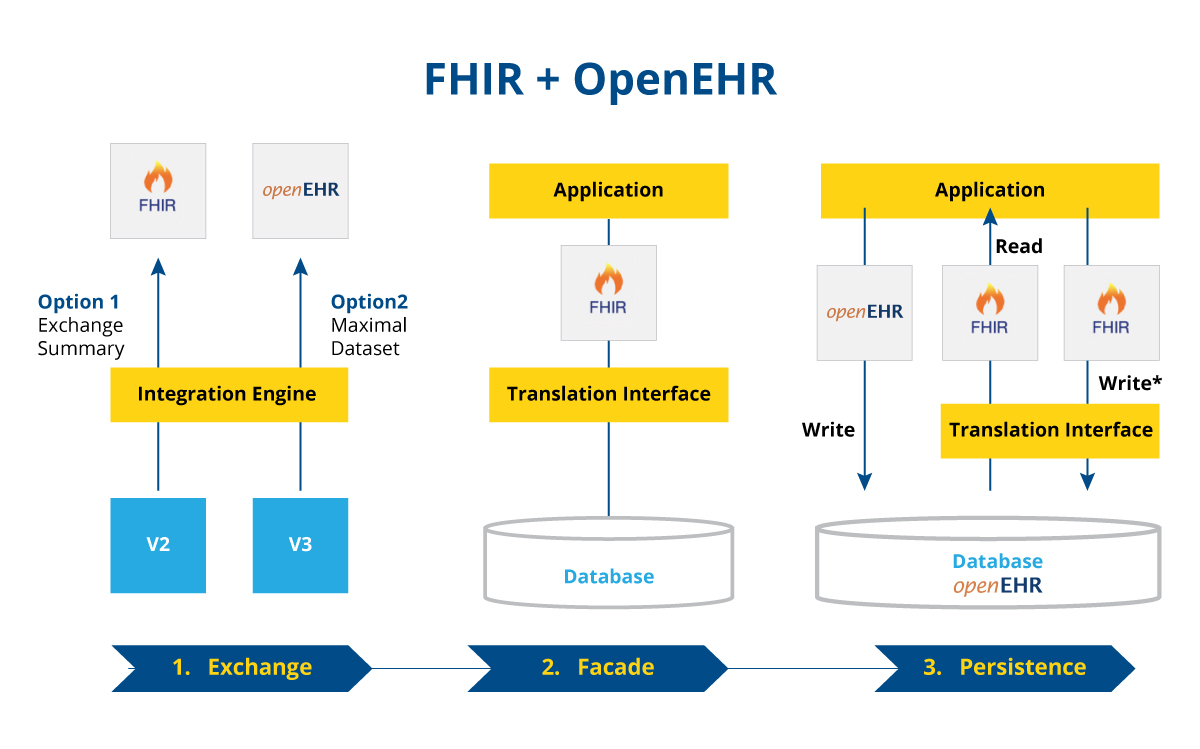
Abbildung 2: Grundlegende digitale Architektur zur Veranschaulichung der kombinierten Nutzung von FHIR und openEHR
Die erste Abbildung zeigt ein grundlegendes interoperables System für den Austausch von Kurzinformationen zwischen Anwendungen. Hier hilft FHIR, die Anwendungssysteme zu verbinden, während openEHR eine bessere Kontrolle über die komplexen Datensätze ermöglicht.
Das zweite Bild zeigt, wie Entwickler openEHR als Übersetzungsschnittstelle für die FHIR-API nutzen können.
Das dritte Bild zeigt eine tiefer gehende Nutzung von openEHR, diesmal als API. In einigen Anwendungsfällen wird die openEHR-API in Verbindung mit der FHIR-API verwendet, um komplexe Datensätze zu erfassen und eine umfassende Interoperabilität zu ermöglichen.
Der Einsatz von FHIR und openEHR in der Cloud-Architektur bietet die folgenden Hauptvorteile:
- Durch die Kombination von openEHR und FHIR können IT-Teams im Gesundheitswesen sicherstellen, dass die Daten in der Cloud auch nach Aktualisierungen der HL7-Standards intakt bleiben.
- Die kombinierte Interoperabilität hilft IT-Teams bei der Skalierung mit verschiedenen Cloud-Lösungen, ohne Angst vor Datenverlust oder Bedeutungsverlust.
- Die von EHR und FHIR festgelegten Standards ermöglichen es Unternehmendes Gesundheitswesens, die von der Cloud gebotenen Möglichkeiten zu nutzen, z. B. die Fernkommunikation mit Patienten und Ärzten.
Die Realisierung dieser Vorteile hängt von der Größe der Gesundheitsakten, der Gesundheitsorganisation, der Anzahl der Patienten und ähnlichen Faktoren ab.
Wir dürfen nicht vergessen, dass sich die Gesundheitsbranche jetzt in einer Phase befindet, in der die Integration ausgereifter und komplementärer Technologien die Wahrnehmung von Patientenergebnissen und der Gesundheit der Bevölkerung verändern könnte. Da Cloud Computing die Skalierbarkeit und Agilität der Unternehmen verbessert, sind robuste Standards für Interoperabilität und Speicherung von entscheidender Bedeutung für die Datennutzung und -speicherung geworden.