
公開日14 Sep 2021
最小読み取り時間
ビュー

2011年、Pentahoの創業者で当時CTOだったジェームズ・ディクソンは、"データレイク "という言葉を生み出した。彼の目的は、従来のデータウェアハウスが抱えていた、エントリー時点での事前分類の必要性という問題を克服することでした。それ以来、私たちはデータウェアハウスやデータレイクのアイデアを先取りし、現在最もホットな話題である "データメッシュ "にたどり着きました。
組織の成功を確実なものにするために、データ主導の意思決定の重要性が世界的に高まる中、これらのコンセプトのそれぞれがどのように業務を可能にするのか、簡単に見てみましょう。
データウェアハウスは、異種ソースからのデータの統合をサポートし、将来の使用のためにデータを分類して保存する。 ここでの運用スキーマは、関連するビジネス要件ごとにあらかじめ構築されており、通常はETL(抽出-変換-ロード)プロセスに従います。
データウェアハウスに関連する課題には、次のようなものがあります:
- 新しいビジネス要件が発生するたびに、スキーマを構築し、ETLプロセスを実装するために、関連するソースとデータを特定する必要がある。
- 既存のスキーマを更新する必要がある場合、データ量が非常に大きくなるため(数テラバイト/ペタバイト)、必要な時間の点で課題となる可能性がある。
- ビジネス・ユーザーによって複数のデータウェアハウスが作成され、分析やBIレポート用の生データや処理済みデータが管理され、ソースの重複につながっている可能性がある。
データレイクは、あらゆる種類のデータを集中型ストアに保存するスキーマレスアーキテクチャの助けを借りて、上記の問題のほとんどを解決するのに役立っている。 データレイクには複数のゾーンが設計されており、データを受け取るためのランディングゾーン(一時データストア)、オリジナルデータを保存するためのローデータゾーン、クレンジングされ処理されたデータが保存されるプロダクションゾーン、機密データを保存するセンシティブゾーン、データサイエンティストやエンジニアが作業するためのデベロッパーゾーンがある。これはロールベースのアクセス管理によって制御される。
データレイクでは、ETLプロセスがELTプロセス(Extract-Load-Transform)に変更され、異種ソースからのすべてのデータがまず単一のストアに集められる(異なるストリームがレイクに流れ込むことを想像してほしい)。データエンジニア、データサイエンティスト、ビジネスアナリストのチームは、主要な結果を動的に導き出すことができる。
そのメリットはともかく、データレイクには以下のような課題がある:
- すべてのデータが一元化されたストアに収集されるため、適切なカタログ化が行われない場合、データ沼が発生する可能性がある。
- データレイクを扱うデータエンジニアは、ビジネスの目標結果を導き出すための深いドメイン理解を必ずしも備えていない。
データ・メッシュ(Data Mesh)は、対応するサービスと似ている。データをビジネス・ドメインに分割し、各ユーザーが関連データを製品として所有することで、各情報を確実にすることで上記の問題を解決する:
- 発見可能
- アドレス指定可能
- 信頼できる真実性
- 自己記述
- 相互運用可能で
- セキュア
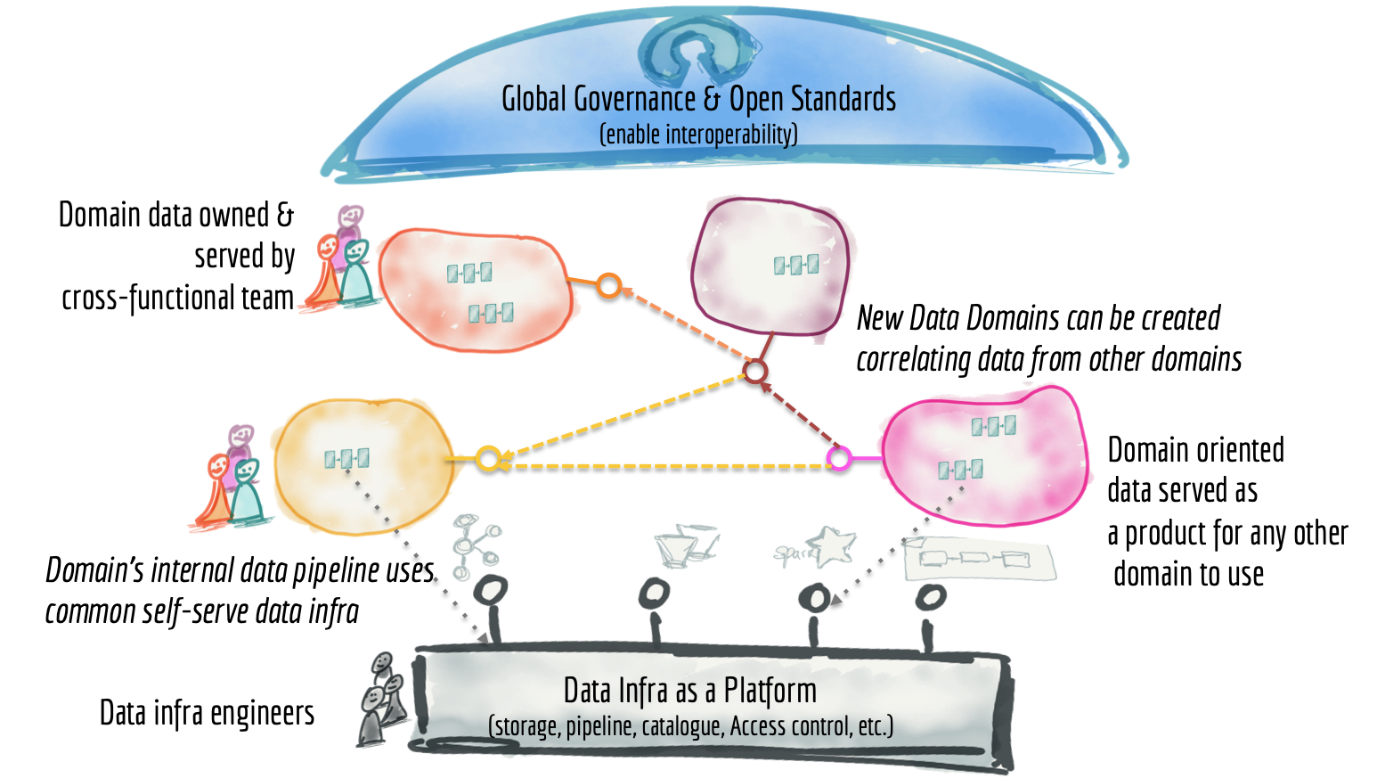
図 1 マーティン・フラワーによる30Kフィートから見たデータ・メッシュ・アーキテクチャ
参考 :https://martinfowler.com/articles/data-monolith-to-mesh.html
データメッシュは、データウェアハウスやデータレイクと共存する新しいパターンである。データウェアハウスが全体的な活動であることに変わりはないが、データレイクはより広範な情報ストアとして機能し、データメッシュによって洞察や分析への迅速なアクセスが可能になる。
データレイク内に仮想的な分離を導入し、データプールやデータポンドに関連する課題の克服を支援することで、データメッシュはこの分野で最もホットな新しいトピックとして浮上している。


