
Published on 14 Sep 2021
min read
Views

In 2011, James Dixon, the founder and then CTO of Pentaho coined the word “Data Lake.” His objective was to help overcome the issues with traditional data warehouses around the need for pre-categorization at the point of entry. Since then, we have surged ahead from the ideas of data warehouses and data lakes to arrive at the hottest topic on the block today – a “Data Mesh.”
With the growing global importance of data-driven decisions for ensuring organizational success, let us take a quick look at how each of these concepts can enable your operations
A data warehouse supports integration of data from heterogeneous sources, and categorizes and stores it for future use. The operational schemas here are prebuilt for each relevant business requirement, typically following the ETL (Extract-Transform-Load) process.
Some of the challenges associated with a data warehouse include:
- For every new business requirement, we need to identify the related sources and data from it to build the schema and implement the ETL process.
- When the existing schema needs to be updated, this could pose a challenge in terms of time requirement as the volume of data can be quite large (several terabytes/petabytes)
- Multiple data warehouses could have been created by business users for maintaining their own raw and processed data for their analytical and BI reports, leading to a duplicity of sources.
Data lakes have helped solve most of the above-mentioned issue with the help of a schema-less architecture for storing any kind of data in a centralized store. They are designed with multiple zones, starting from landing zone to receive the data (temporal data store), raw data zone to store the original data, production zone where the cleansed and processed data is stored, sensitive zone to store the sensitive data, and dev zone for the data scientist and engineer to work on. This is controlled via role-based access management.
With data lakes, the ETL process is now changed to ELT process (Extract-Load-Transform), all data from heterogeneous sources is first collected in a single store (imagine different streams flowing into a lake). The team of data engineers, data scientists, and business analysts can the derive the key results dynamically.
Its benefits notwithstanding, data lakes have their own set of challenges, including:
- All data is collected into a centralized store, which can result in a data swamp in the absence of proper cataloging.
- Data engineers who deal with a data lake are not always equipped with a deep domain understanding for deriving the target results for the business.
A data mesh similar to its counterpart service. It solves the above problem by breaking the data into business domain where each user will own the relevant data as a product to ensure that each piece of information is:
- Discoverable
- Addressable
- Trustworthy and Truthful
- Self-describing
- Inter-operable, and
- Secure
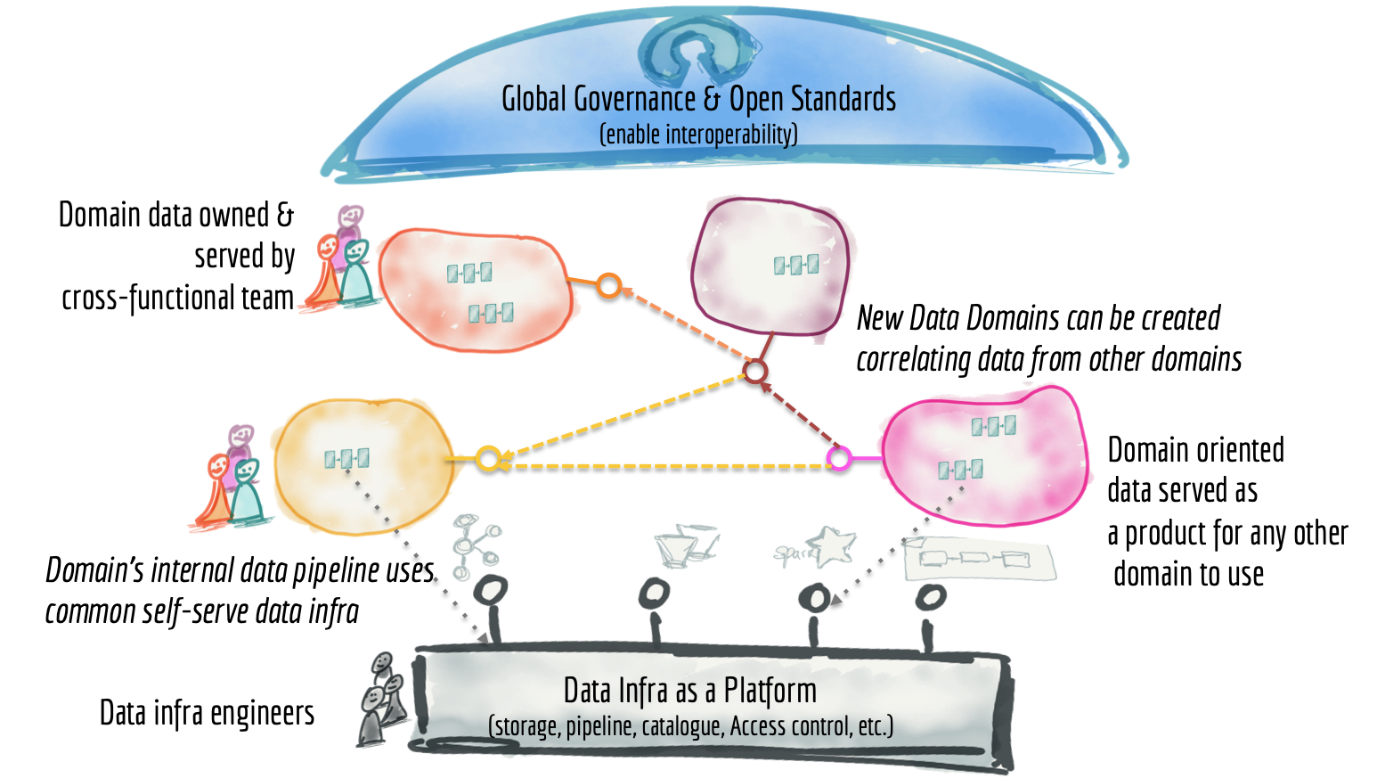
Figure 1 Data Mesh architecture from 30K foot view by Martin Flower
Ref: https://martinfowler.com/articles/data-monolith-to-mesh.html
Data mesh is a new pattern which co-exists with the data warehouse and data lakes. While data warehousing remains the overall activity, data lakes act as a wider information store, with the data mesh enabling a faster access to insights and analytics.
By introducing a virtual separation within a data lake and helping overcome the challenges associated with a data puddle or data pond, a data mesh has therefore emerged as the hottest new topic in the domain.


